使用”noindex”等4種方式禁止特定網頁被收錄,提升網站整體seo品質

收錄基本概念:
最開始,讓我們簡述一下在這篇文章反覆出現的字眼—收錄,在SEO中到底扮演甚麼樣的腳色。一般來說,搜尋引擎的機器人(google bot)會根據網頁之間的連結進行移動,藉以爬取整個網路,這個過程稱為檢索(crawl),爬完網頁資料後會把有用的資料放進資料庫,這個過程稱為索引(index)同時也就是本篇的主題 – 收錄。
沒有被收錄,就不可能出現在搜尋結果中,更不用談排名了。對SEO來說,網站能夠被正確收錄是非常重要的,不過收錄並不是單純的越多越好,如果一個網站收錄了很多對搜尋結果沒有幫助的網頁,反而會讓搜尋引擎認為網站的內容空洞,可能會讓網站的權重下降。所以排除這些不重要頁面也是SEO中一個有用的方向。
額外補充:有的人以為網站完全沒有外部連結進入,也沒有對搜尋引擎進行提交,就不會被收錄,這是不正確的!! 以google目前的技術來說,這樣的網站還是有很高的機會進行收錄,尤其是當網站使用比較主流的CMS系統(例如:wordpress),在建置期間就被收錄的可能性是很高的,而過早的收錄其實會對後續SEO優化造成困擾,建議一定要進行正確的設定,避免後續的麻煩。
不需要收錄的狀況:
甚麼時候不要被搜尋引擎收錄比較好? 以下舉出幾種常見的狀況:
-
未完成、測試中的網站:
未完成的頁面中的資料通常都是不完整、甚至是不正確的,如果在這個階段被搜尋引擎收錄,可能會導致兩個壞處:一、讓使用者產生困惑。二、讓搜尋引擎誤會網站擁有的內容品質不好。
而測試中與正在建立的網站如果被收錄,很可能會造成未來的正式網站與測試空間的內容重覆,處理的不好還可能被搜尋引擎當成是重複內容,甚至是抄襲。對SEO無疑是很大的扣分,建議要避免發生這樣的狀況。 -
隱密資料、不想公開的內容:
不少網站中存有使用者資料、公司的內部資料、後台環境、資料庫…等等,如果伺服器設定不正確,沒有確實的阻擋搜尋引擎的爬取與收錄,這些內容也是有可能會被收錄並直接公開到網路上的,過去也確實發生過類似的案例。
這些資料被收錄面臨的問題可能就不只是SEO了,如果是涉及敏感的合約書、契約書…等等,可能還會有法律上的責任。 -
不重要頁面
這是最多網站會發生,也是與SEO最有關的情況,網站或多或少都會包含一些沒有搜尋價值的頁面,例如:版權聲明、法律條款、登入頁面、結帳確認頁面、測試結果、使用者資料頁…等等,當這些頁面在收錄頁面中的比例太高時,有可能就會被搜尋引擎誤會網站的內容空洞,因此傷害到網站權重。
另外,用wordpress建置的網站除了上述的情況外,還會出現更多不重要頁面的問題,由於wordpress預設下只要上傳圖檔或者是附件的時候,就會自動生成一個頁面(例如:https://www.awoo.com.tw/blog/9/)這個頁面就是上傳檔案時自動生成的頁面,由於這樣的機制,wordpress建置的網站在預設的情況下會產生大量的多餘頁面,如果沒有進行相關的處理,就可能會傷害到SEO。要解決這個問題可以利用簡單的wordpress外掛:Noindex Attachment Pages。
如何查詢網站是否收錄了多餘頁面?
我們已經知道在甚麼情況下可能會需要排除網頁收錄,在這裡順便分享一下如何去查詢是否有收錄奇怪頁面的方式:
1. 利用site查詢:
site是搜尋引擎中的進階指令,在google的搜尋框中打入:site:要查詢的網域名稱,就可以找到google收錄的部分網址,在這裡的搜尋結果中很容易可以看到收錄的多餘頁面。

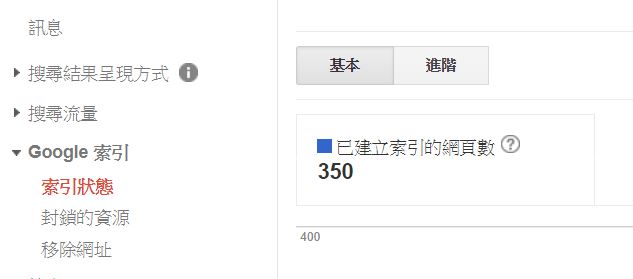
2. 查看search console中收錄數與實際頁面做對比:
search console是察看google收錄最準確數目的工具,查看裡面的 Google索引 > 索引狀態 就可以找到google的收錄數目,把這個數目與網站中實際有效的頁面做對比,也可以看出google有沒有收錄過多的情況。
排除收錄的方法:
我們已經知道什麼狀況需要排除這些頁面,接下來讓我們看看如何做到這件事:
- <meta> noindex標籤: 利用「noindex」封鎖搜尋索引服務,在不希望被收錄的網頁<head>中使用以下指令:
- <meta name=”robots” content=”noindex”> 1 <meta name=”robots” content=”noindex”> 詳細的使用方式可以查看:google的官方說明,利用這個方法可以有效的解決不想要被收錄頁面。也是比較推薦的方式,不過缺點也很明顯,如果頁面數太多可能會有執行上的困難。 優點:可以解決大多數的問題,操作容易
缺點:需要單頁設定,如果頁面數量大會有執行困難 - 利用 robots.txt 檔案: robots.txt 檔案位於網站根目錄,能夠向搜尋引擎檢索器表明您不希望檢索器存取的網站內容。在大多數的情況下都可以解決不想被收錄的問題,不過 robots.txt 本身還是有一些限制的,在google官方的說明中就有表明幾種狀況下 robots.txt 可能會失效:
a. robots.txt 不是強制的指令,因此不是每個搜尋引擎都會完全遵守 robots.txt 內的指令
b. 不同引擎解讀 robots.txt 的方式可能會有差異,導致沒有檔案生效
c. 以google來說,如果有足夠外部連結指向網頁可能也會讓網頁被收錄,既使在 robots.txt 中是禁止的。 優點:robots.txt 設定方便,能夠一次解決同一頻道下的所有頁面,絕大多數的情況下能解決問題。
缺點:在某些情況不會有效,並且由於設定是針對整個資料夾,如果設定錯誤可能會導致整個網站的收錄都出問題,這樣就會影響到舊有的排名。 - 伺服器設定解決: 直接在伺服器上把檔案設定成密碼存取,或者擺在需要密碼存取的資料夾內。例如使用Apache 網頁伺服器時,可以編輯 .htaccess 檔案使伺服器目錄受密碼保護。如此一來就可以保證搜尋引擎不會抓取,這是最根本且絕對有效的方式,不過這樣設定也代表了一般使用者無法在網路上查看網頁,可能會不符合網站設計的目的,因此這個方法通常只適合應用在敏感的資料上。 優點:能夠根本性的隱藏不想被找到的內容。
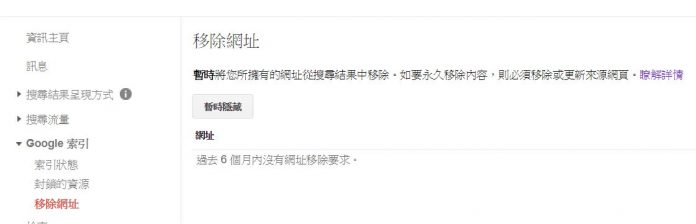
缺點:設定隱藏的內容一般使用者無法瀏覽。 - 利用網站管理員平台設定: 有些網站管理員有這方面的設定可以用來對所屬的搜尋引擎提出宣告,例如:google 的 search console就有這個設定(移除網址),不過利用這個方法的缺點也很明顯,就是只能針對單一的搜尋引擎生效,對其他搜尋引擎是無效的。 優點:設定方便,不需要涉及到程式碼
缺點:只能針對單一搜尋引擎,移除得不徹底,同時不同的網站管理員平台可能對這個指令有不同的用途,不一定能達成我們希望的SEO目的。
最後總結:
當我們利用以上的方式去設定、排除掉一些不需要被收錄的網站,讓搜尋引擎收錄的頁面品質提高,對SEO是有一定幫助的,不過在實際操作中,一定要特別注意不要設定錯誤,如果因為不小心或者搞錯網頁,讓原本有重要排名的頁面被移除收錄,對網站的SEO是有致命性的傷害的!! 因此一定要非常確定執行下會影響到的頁面。